
Agentic RAG based Chatbot System for Skill Lync
A Retrieval-Augmented Generation (RAG)–based AI learning assistant for a large engineering-focused EdTech platform.
Executive Summary
Cybermind Works created a Retrieval-Augmented Generation (RAG)–based AI learning assistant for Skill-Lync, a large engineering-focused EdTech platform. The goal was to develop a secure and scalable system that allows students to search through and understand thousands of hours of recorded courses, workshops, project materials, and platform information, while safeguarding paid content and maintaining academic integrity.
This solution was designed as an AI chatbot featuring structured content ingestion, intelligent search and retrieval, access-controlled responses, result reranking, monitoring, and ongoing evaluation.
Client Context
Skill-Lync is a premium EdTech provider offering:
- 500+ recorded engineering courses
- Recorded workshops and masterclasses
- Hands-on, graded projects
- Extensive documentation around program structure, schedules, and placements
As the platform scaled, students faced difficulty navigating large volumes of content, while mentors and support teams handled repetitive questions. The client wanted to introduce AI in a way that augmented learning, reduced support load, and maintained strict control over paid content.
Problem Statement
Relevance in Large-Scale Learning Content
- Students need clear, context-specific answers, not generic summaries
- Relevant explanations are often buried deep inside lengthy lectures
- Traditional search methods fail to surface the right segment at the right time
Fragmented Data
- Thousands of hours of learning content spread across courses, workshops, and masterclasses
- Platform knowledge scattered across several data sources, ranging from video transcripts, PDF, PPT, notes, web pages, FAQs, program information, and help documentation
- No unified way to navigate or connect related data
Mentor and Support Bandwidth
- Students frequently ask questions already covered in course material
- Significant time spent answering "where is this explained?" queries
Strict Content Gating
- Paid course and workshop content with controlled access
- Zero tolerance for content sharing across different courses or workshops
Project Guidance Without Revealing Answers
- Students need help understanding project requirements and expectations
- Direct answers, solutions, or code generation must be avoided
Production Requirements
- Full observability
- Deterministic behavior
- Regression-safe deployments
Solution Overview
Cybermind Works created a production-grade Agentic RAG system that serves as a learning assistant rather than a typical chatbot. The system supports:
- Recorded courses
- Recorded workshops and masterclasses
- Conceptual guidance without answer leakage
- General platform and program information
- Upselling flows and scheduling calls with technical support engineers
System Architecture (Overview)
Overall Architecture
High-level view of the RAG-based learning assistant system
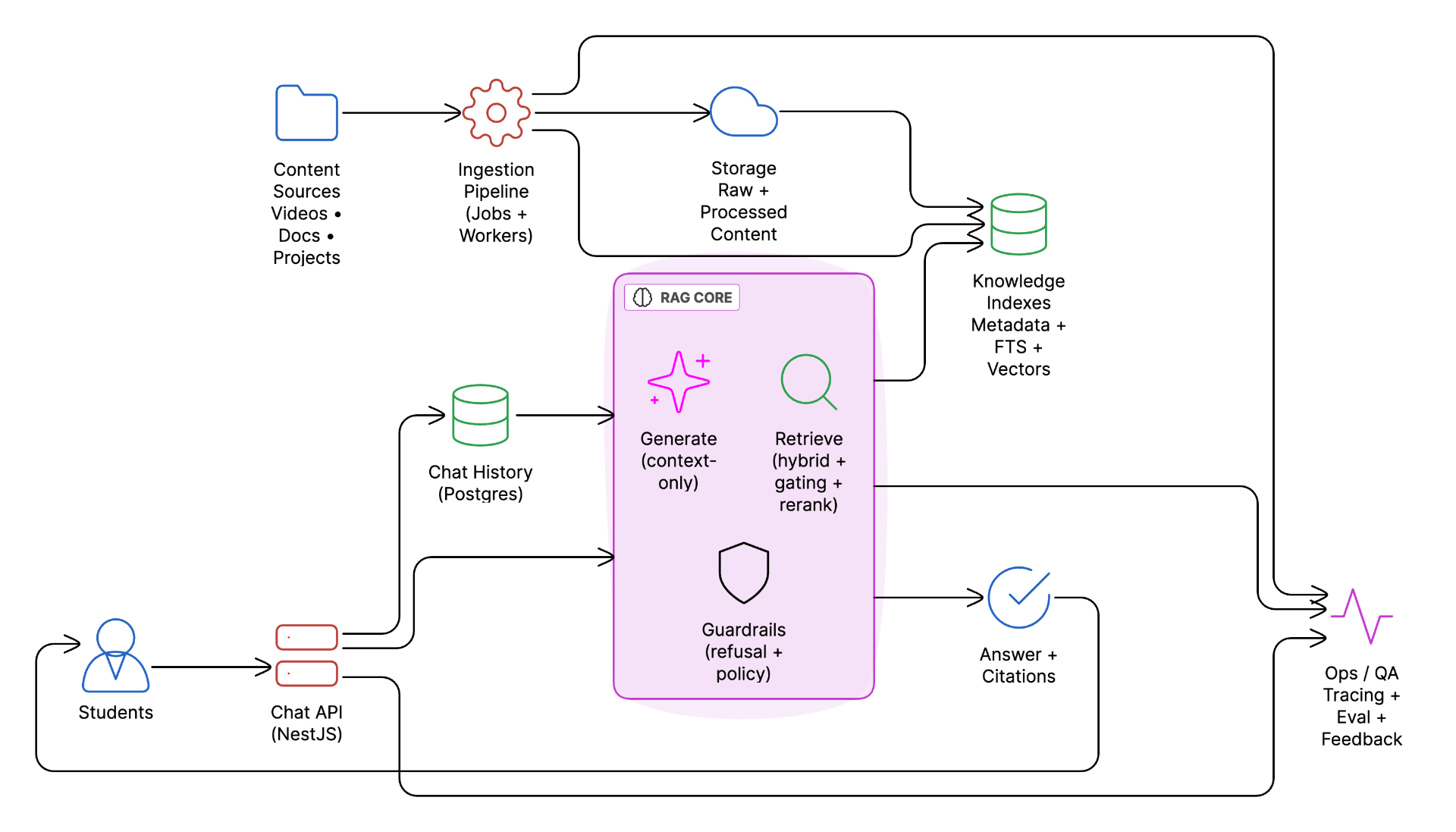
The platform is designed as a reliable learning intelligence system. The architecture prioritizes scalability, predictable costs, academic integrity, and learner trust, while remaining simple enough for dependable large-scale operation.
The system consists of six tightly integrated subsystems, each addressing a core challenge in deploying AI for large-scale learning platforms:
Data Ingestion Pipeline
Data Ingestion Pipeline Architecture
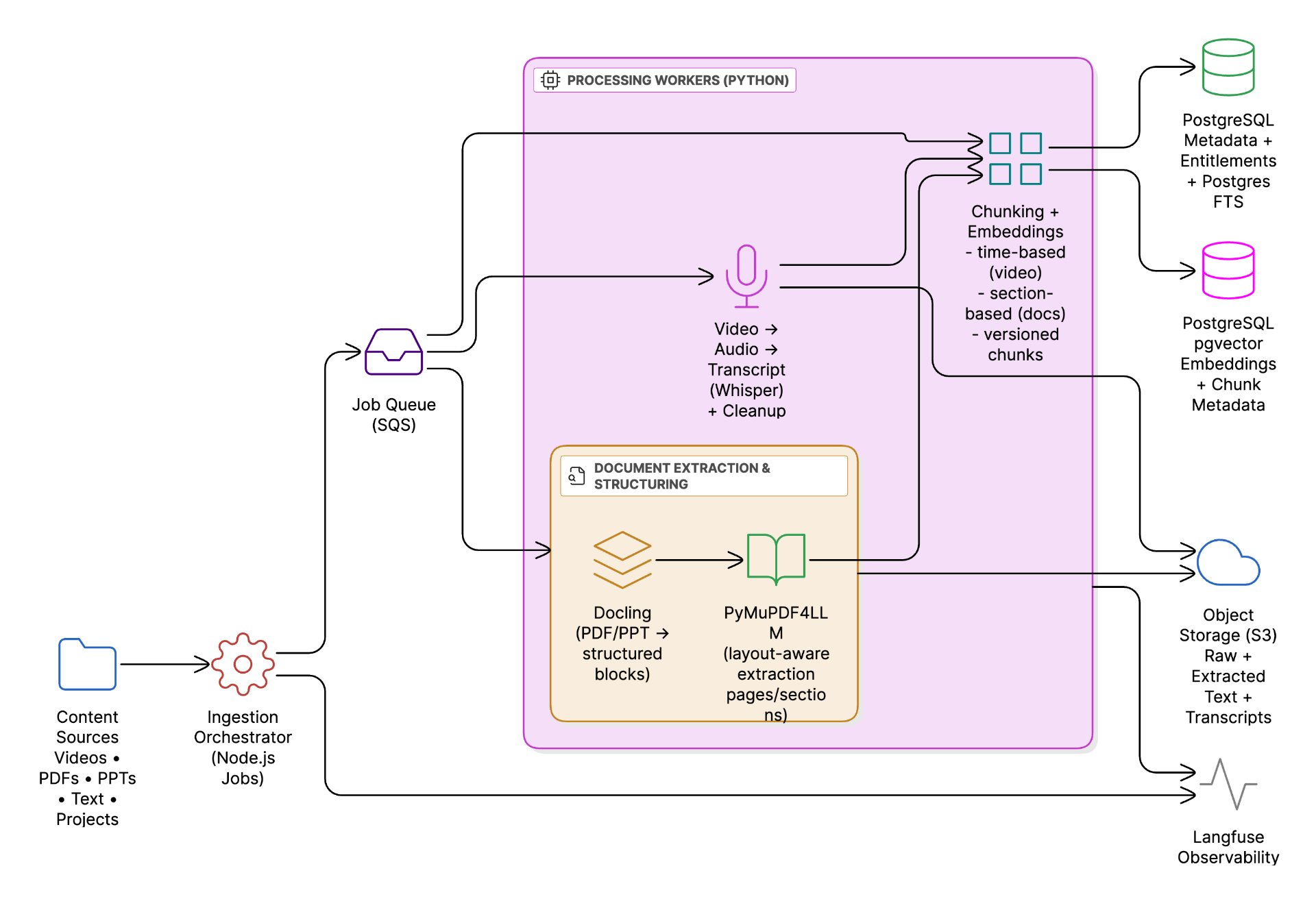
The ingestion pipeline is fully asynchronous and job-driven, allowing content updates to scale independently of learner traffic. This separation is essential because courses, workshops, and learning materials are frequently updated.
Content Types Supported
- Recorded videos
- PDFs, PPTs, and instructor notes
- Platform-level documentation
Orchestration and Queuing
Ingestion is orchestrated using Node.js services, with each ingestion task pushed to Amazon SQS. This enables:
- Reliable retry handling
- Back-pressure control
- Horizontal scaling
- Zero impact on live learner queries
Video and Workshop Processing
For videos:
- Audio is extracted from videos
- Whisper-based speech-to-text generates timestamp-aligned transcripts
- Transcripts are cleaned and normalized for consistency
- Timestamp alignment is preserved to enable precise, citation-backed answers
Document Processing
Specialized open-source libraries are used to process documents like PDFs and PPTs:
- Docling is a document understanding library that preserves logical sections and content hierarchy while extracting structured blocks.
- A layout-aware parsing library called PyMuPDF4LLM allows page-level extraction while preserving pagination and spatial context.
Change Detection and Incremental Ingestion
Each content item is tracked using: updated_at, last_ingested_at, content hash. During every synchronization cycle, timestamps and hashes are compared. Only new or modified content is sent to the ingestion queue. This approach:
- Prevents unnecessary reprocessing
- Keeps ingestion costs predictable
- Supports frequent curriculum updates without downtime
Chunking and Embeddings
Content is chunked using a recursive character-based splitter, producing chunks of 800–1200 words. This method was chosen over semantic chunking due to scale and cost considerations, while still delivering stable retrieval performance. Each chunk is enriched with metadata such as course ID, lesson, workshop, timestamps, or page numbers. Embeddings are generated and stored in PostgreSQL using pgvector, enabling incremental re-indexing driven by timestamps and content hashes.
Hybrid Retrieval and Indexing
Hybrid Retrieval Pipeline
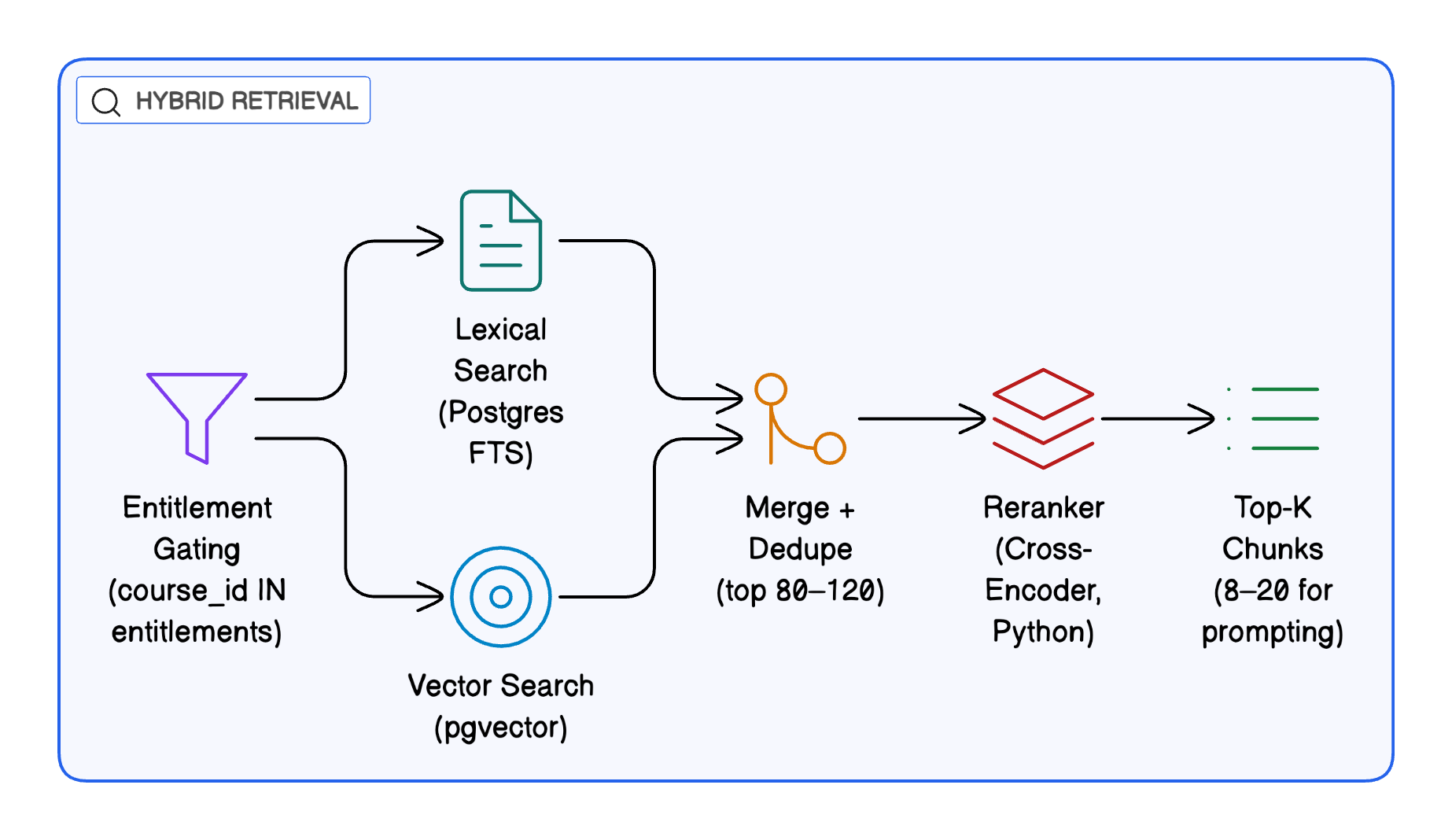
At query time, the system performs hybrid retrieval, combining semantic understanding with exact matching to mirror real learner behavior.
- Semantic retrieval uses pgvector embeddings with cosine similarity, supporting conceptual and paraphrased queries.
- Lexical retrieval uses PostgreSQL Full-Text Search, handling keywords, formulas, acronyms, and code-related terms.
- Both retrieval paths operate independently. Results are then merged, deduplicated, and filtered using metadata-based access control before downstream processing. This ensures learners only access entitled content while maximizing recall and precision.
Agentic Query Orchestration
Single RAG Agent Architecture
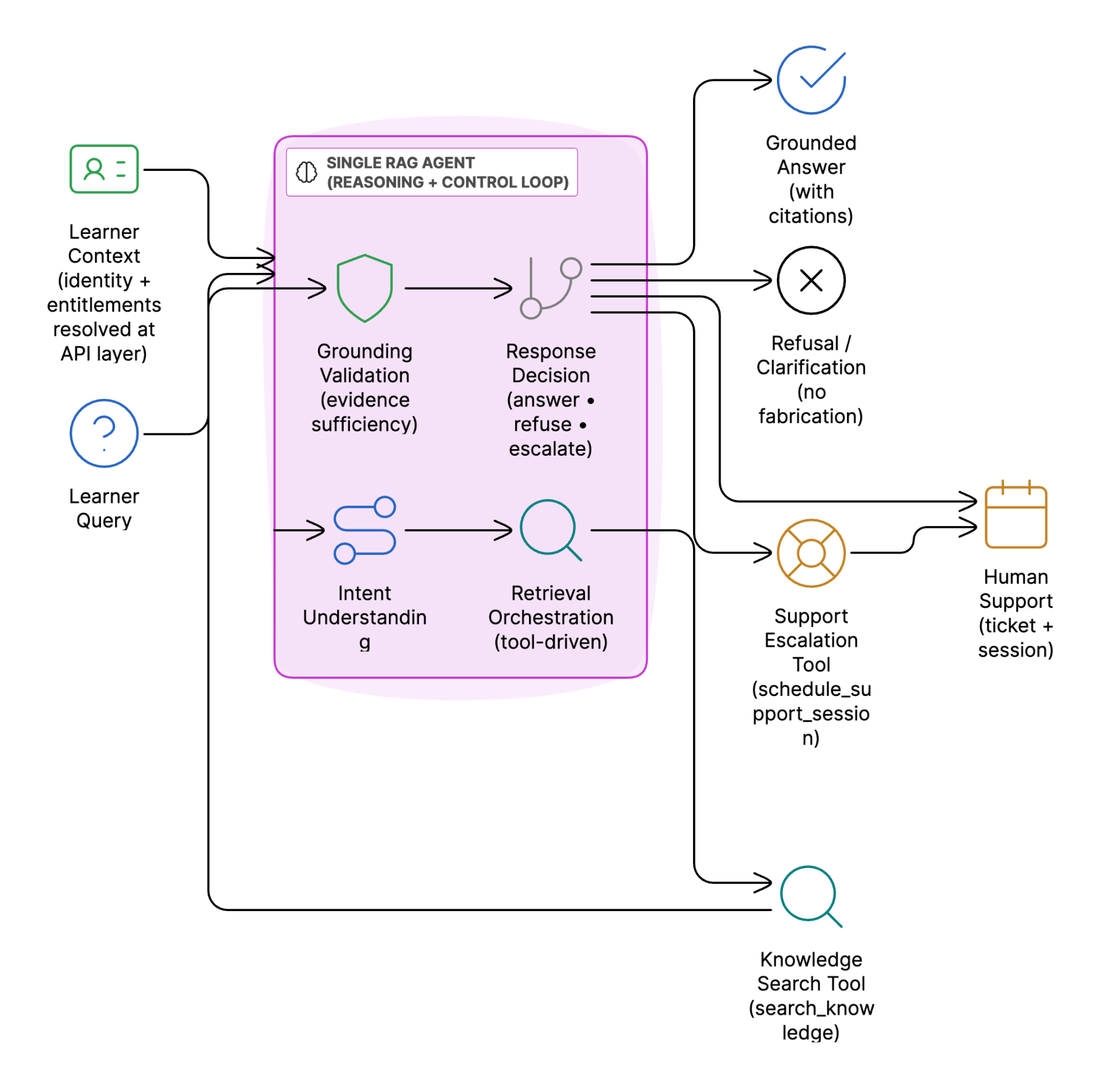
Core Tools Used by the RAG Agent
| Tool Name | Purpose | Key Responsibilities |
|---|---|---|
Knowledge Search Tool search_knowledge(query: string, max_results: number) | Retrieves authoritative, learner-accessible knowledge for answering queries |
|
Support Escalation Tool schedule_support_session(topic: string, priority: enum) | Escalates queries that cannot be safely or accurately answered by the system |
|
The platform uses a single-agent Agentic RAG architecture, avoiding linear prompt chains or complex multi-agent setups. This design keeps behavior predictable and production-ready while still enabling agent-style reasoning and tool usage.
A single RAG Agent manages the full reasoning loop per learner query, including:
- Intent understanding
- Retrieval orchestration
- Grounding validation
- Answer generation
- Refusal or escalation when needed
For each query, the agent determines whether it relates to:
- Course lessons
- Recorded workshops
- Projects
- General platform information
Learner identity and entitlements are resolved at the API layer, allowing downstream tools to naturally enforce access control. Before generating any response, the agent verifies that sufficient and relevant evidence exists. Speculative, ungrounded, or policy-violating responses are explicitly blocked.
Reranking and Grounded Answer Generation
Reranking & Grounded Answer Pipeline
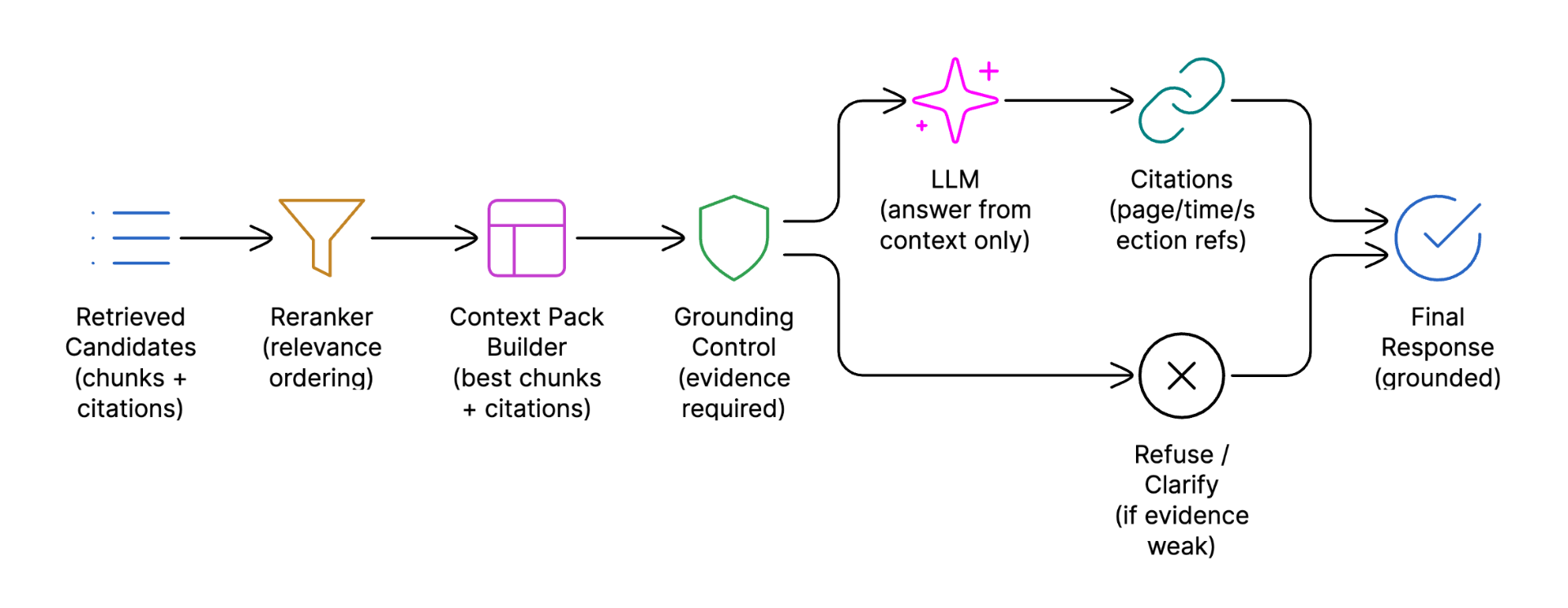
In large learning platforms, simply "finding related content" is not enough. Early-stage AI systems often overwhelm users by passing too much loosely related material to the language model, which can result in fragmented answers, missed details, or confident-sounding but incorrect responses.
To ensure learners receive precise, trustworthy, and syllabus-aligned explanations, the system must carefully select only the most relevant evidence before generating an answer. To address this, Skill-Lync's AI assistant introduces an explicit reranking and grounding layer that acts as a quality gate between content retrieval and answer generation.
Retrieved results are passed through a cross-encoder reranker, implemented as a standalone Python service. It evaluates query–chunk relevance and selects the most useful context, typically the top 10–12 chunks.
The LLM receives only this reranked context when generating responses. All answers include explicit citations, such as timestamps or page numbers. If adequate evidence is unavailable, the system either declines to answer or requests clarification. This approach significantly reduces inaccuracies and builds learner trust.
Observability and Debugging
Observability Pipeline
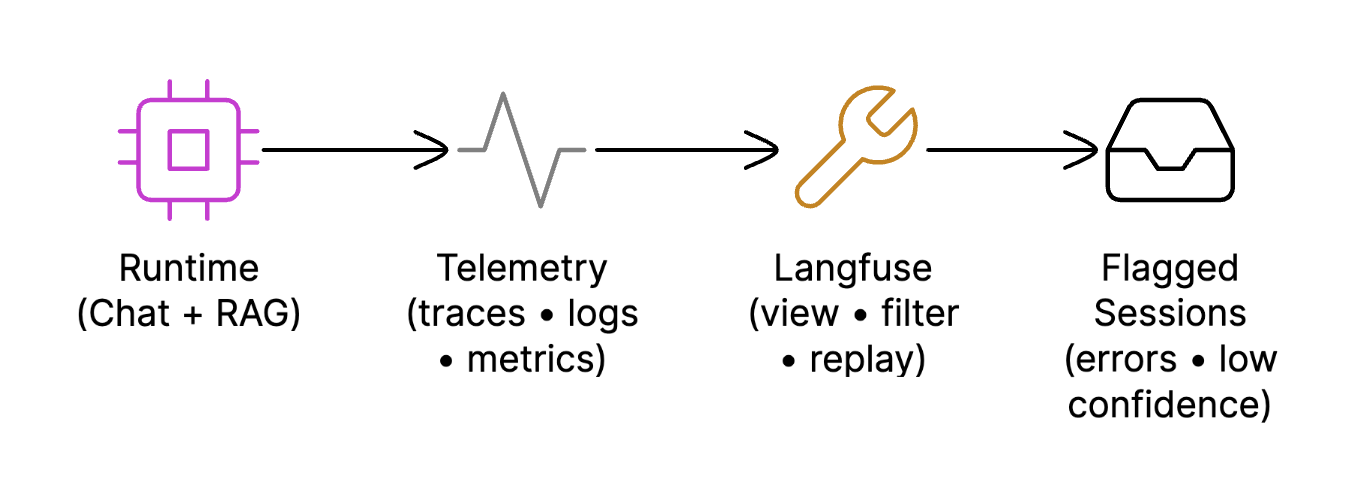
Seeing how and why decisions are made is necessary to run an AI system at scale. Problems like inaccurate responses, increasing expenses, or poor performance become challenging to identify and dangerous to resolve in the absence of clear observability. The platform is made to be completely observable from beginning to end.
The platform is fully instrumented using Langfuse, capturing signals such as:
- Agent decisions
- Retrieval candidates and scores
- Reranking output
- Prompts and responses
- Token usage and latency
Testing and Evaluation
Evaluation Framework
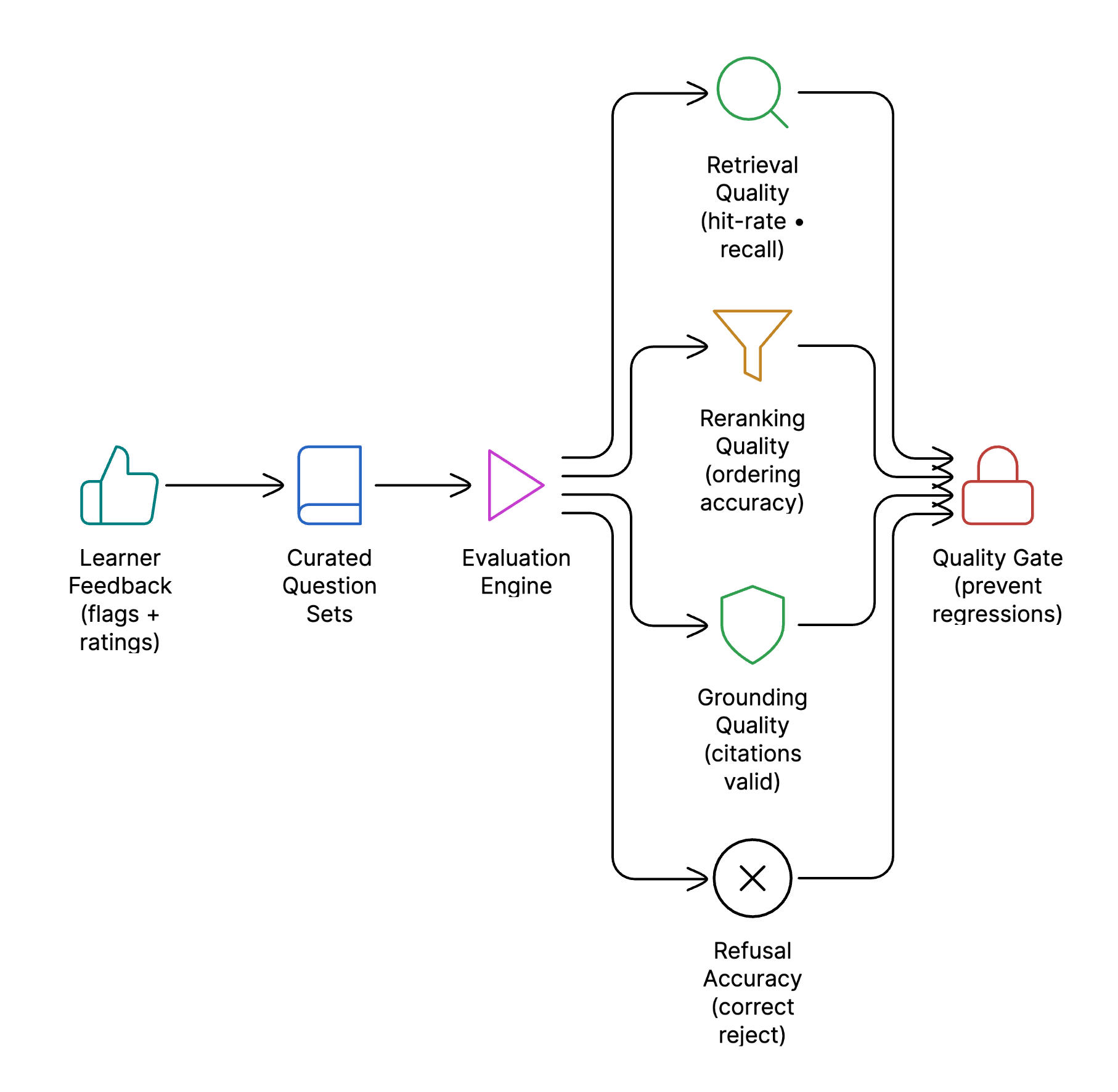
AI systems lose accuracy as curricula evolve and content expands. Even minor changes to prompts, retrieval logic, or models can subtly deteriorate answer quality or introduce inconsistencies across courses in the absence of systematic testing. We created a dedicated, ongoing evaluation framework to guarantee the learning assistant stays dependable, predictable, and in line with instructor intent.
Curated question sets are maintained across courses, workshops, and projects, and are continuously expanded as the platform evolves. Each change is evaluated using a combination of automated metrics and LLM-based evaluation, measuring:
- Answer relevance
- Grounding quality
- Citation accuracy
Learner feedback plays a direct role in quality improvement. Flagged responses and recurring failure patterns are converted into new test cases and incorporated into the evaluation suite.
Challenges Faced and How We Solved Them
This section outlines the practical engineering challenges faced while building and operating the Skill-Lync AI chatbot in production.
Continuous Content Updates Across Hundreds of Courses
Problem:
Skill-Lync regularly updates course videos, workshop recordings, PDFs, and project documents. A naive approach of re-ingesting all content during every update quickly became impractical due to:
- High compute and embedding costs
- Long ingestion and downtime windows
Solution:
We implemented incremental ingestion using updated_at timestamps and content hashing:
- Each content item stores last_ingested_at and a content hash
- During every sync cycle, the system compares the latest updated_at value and recalculated hash
- Only new or modified items are pushed to the queue for ingestion
Cost Optimised Chunking at Scale
Problem:
While semantic chunking initially appeared attractive, it was quite expensive:
- Hundreds of courses and workshops
- Thousands of PDFs and long video transcripts
- Significantly increased preprocessing time and embedding costs
Solution:
We adopted a recursive character-based text splitter with chunk sizes between 800–1,200 words:
- Deterministic chunk boundaries
- Substantially lower preprocessing and embedding costs
- This trade-off preserved acceptable semantic recall while keeping infrastructure costs under control.
Poor Answer Quality with Pure Vector Search
Problem:
Early implementations using only vector-based semantic search resulted in:
- Missed exact terms (formulas, acronyms, parameter names)
- Incorrect ranking for highly technical queries
Solution:
We implemented hybrid retrieval:
- Semantic search using pgvector with cosine distance
- Lexical search using PostgreSQL Full-Text Search (FTS) for exact keyword matching
- Results from both systems were merged, cleaned, and re-ranked, significantly improving recall for technical queries without sacrificing conceptual understanding.
Example (Skill-Lync Full Stack context):
A learner asked: "What are the different types of joins explained in Everything about Database – 2.0, and when should each be used?"
Relevant information exists clearly within Everything about Database – 2.0, where joins are explained using:
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
along with usage scenarios
However, with pure semantic search, the system often retrieved:
- High-level explanations about relational databases
- Conceptual discussions about tables and relationships
- General SQL theory without explicitly covering each join type
Because vector search prioritizes semantic similarity, chunks that explicitly listed and compared specific JOIN types were sometimes ranked lower than broader conceptual text.
As a result:
- Answers missed exact JOIN classifications
- Learners received partial or vague explanations
- Important syllabus-level distinctions were lost
Solution:
We implemented hybrid retrieval combining:
Semantic search (pgvector)
To capture conceptual explanations around database relationships
Lexical search (PostgreSQL Full-Text Search)
To guarantee retrieval of exact syllabus terms like:
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
Results from both systems were:
- Merged
- Deduplicated
- Re-ranked before passing to the answer generation layer
Inaccurate Chunk Selection
Problem:
Even with hybrid retrieval, the top-K results (chunks) often contained partially relevant or noisy chunks, especially for longer or multi-part questions.
Solution:
We introduced a cross-encoder reranking service (Python-based):
- Scores query–chunk relevance
- Selects the top 10–12 highest-quality chunks
- Applies diversity constraints to avoid repetitive content
- This dramatically improved answer precision and reduced irrelevant context passed to the LLM.
Example:
A learner asked: "How is an end-to-end e-commerce application structured in the program?"
Relevant information exists across multiple officially listed components:
- UI and interaction concepts from The Complete Front-End Development – 2.0
- Backend service design from Microservices using Java, Spring & Docker
- Data modeling concepts from Everything about Database – 2.0
- Applied implementation from the real e-commerce platform project
However, initial retrieval often returned:
- A chunk explaining frontend page structure only
- Another chunk describing database normalization
- A generic overview of microservices without project linkage
- Course introductions rather than project-specific architecture
Passing all of these raw chunks to the LLM resulted in:
- Fragmented answers
- Missing connections between courses
- High-level explanations without showing how the pieces fit together
Solution:
We introduced a cross-encoder reranking service (Python-based) that operates after hybrid retrieval:
- Jointly scores query–chunk relevance
- Prioritizes chunks that: Reference the e-commerce platform project, Connect multiple course concepts together
- Selects only the top 10–12 highest-quality chunks
- Applies diversity constraints so selected chunks include: Frontend structure, Backend service interaction, Database role within the project
Only these refined chunks are passed to the LLM.
Risk of Cross-Course and Cross-Workshop Content Leakage
Problem:
Skill-Lync operates under a strict paid-access model. Any leakage of content from unenrolled courses or workshops was unacceptable.
Solution:
We enforced metadata-based access control at retrieval time, not during generation:
- Each chunk is tagged with course_id, workshop_id, or project_id
- User entitlements are validated before retrieval
- Unauthorized content is never retrieved or exposed to the LLM
- This provided strong isolation guarantees and eliminated the risk of content leakage.
Example:
A learner enrolled just in The Complete Front-End Development – 2.0 asked: "Show me the Java Spring Microservices configuration used in the insurance policy project."
Without strict content gating:
- Vector-based retrieval could mistakenly pull chunks from Microservices using Java, Spring & Docker
- Or project files describing REST API implementations and service registration
- Even though the learner hasn't started backend or microservices courses yet
This would inadvertently expose advanced backend design patterns or microservices architecture that the learner has not been taught yet in their current modules.
Solution:
We enforce metadata-based access control at retrieval time:
- Each chunk is tagged with its corresponding course or project (e.g., Angular Web Development, Microservices using Java, Spring & Docker, e-commerce project)
- The learner's entitlements are checked before any retrieval
- Retrieval queries are filtered so only authorized course content is considered
Hallucination and Over-Confident Answers
Problem:
LLMs tend to generate confident answers even when supporting evidence is weak or missing, which is especially dangerous in an educational context.
Solution:
We enforced a retrieval-first, grounding-controlled generation strategy:
- Responses are generated only from retrieved context
- Mandatory citations (timestamps or page numbers) are required
- The system explicitly refuses or asks for clarification when evidence is insufficient
- This significantly improved student trust and reduced the spread of misinformation.
Example:
A student asked: "Show the exact Spring Boot configuration used in the course to secure REST APIs using JWT authentication."
If the system failed to retrieve:
- The specific Spring Security configuration class
- The exact usage of annotations like @EnableWebSecurity, OncePerRequestFilter, taught in the course
A naive LLM could:
- Invent a generic JWT setup
- Use annotations or configurations not covered in the course
- Present a solution that compiles, but does not match what the instructor taught
This creates confusion for learners when their implementation differs from:
- Recorded lectures
- Project structure
- Instructor walkthroughs
Solution:
We enforce a retrieval-first, grounding-controlled generation strategy:
- Answers are generated only from retrieved course material
- Mandatory citations are attached, such as: Course module name (e.g., Backend Development using Java & Spring Boot), Specific lesson or project reference, Configuration class or file name used in the course
If the required configuration or code is not present in retrieved content, the system:
- Refuses to fabricate an answer
- Asks the learner to clarify the question or guides them to the exact lesson where the topic is covered
- Offers the option to schedule a discussion with a Skill-Lync technical support engineer or mentor for deeper, personalized guidance
Debugging and Operating LLMs in Production
Problem:
Without strong observability, it is impossible to understand why answers fail, where costs spike, or how quality degrades over time.
Solution:
We integrated Langfuse for full-stack observability:
- Retrieval and reranking traces
- Prompt construction and token usage
- Latency and cost monitoring
- End-to-end query execution visibility
- This enabled safe iteration, rapid debugging, and confident production deployments.
Continuous Hyperparameter Tuning Without Regressions
Problem:
Retrieval quality is highly sensitive to hyperparameters such as chunk size, hybrid retrieval weights, top-K limits, and reranker thresholds. Small tuning changes can silently degrade answer relevance, grounding quality, or citation accuracy across existing courses and workshops.
Solution:
We introduced a continuously maintained Curated Test Case Set derived from real learner queries:
- Curated questions span courses, workshops, projects, and platform information
- Every tuning change is evaluated against this dataset using automated metrics (grounding score, citation precision, refusal correctness)
- Only configurations that pass regression thresholds are promoted to production
- This ensured safe, continuous optimization while preventing quality regressions in live learner experiences.
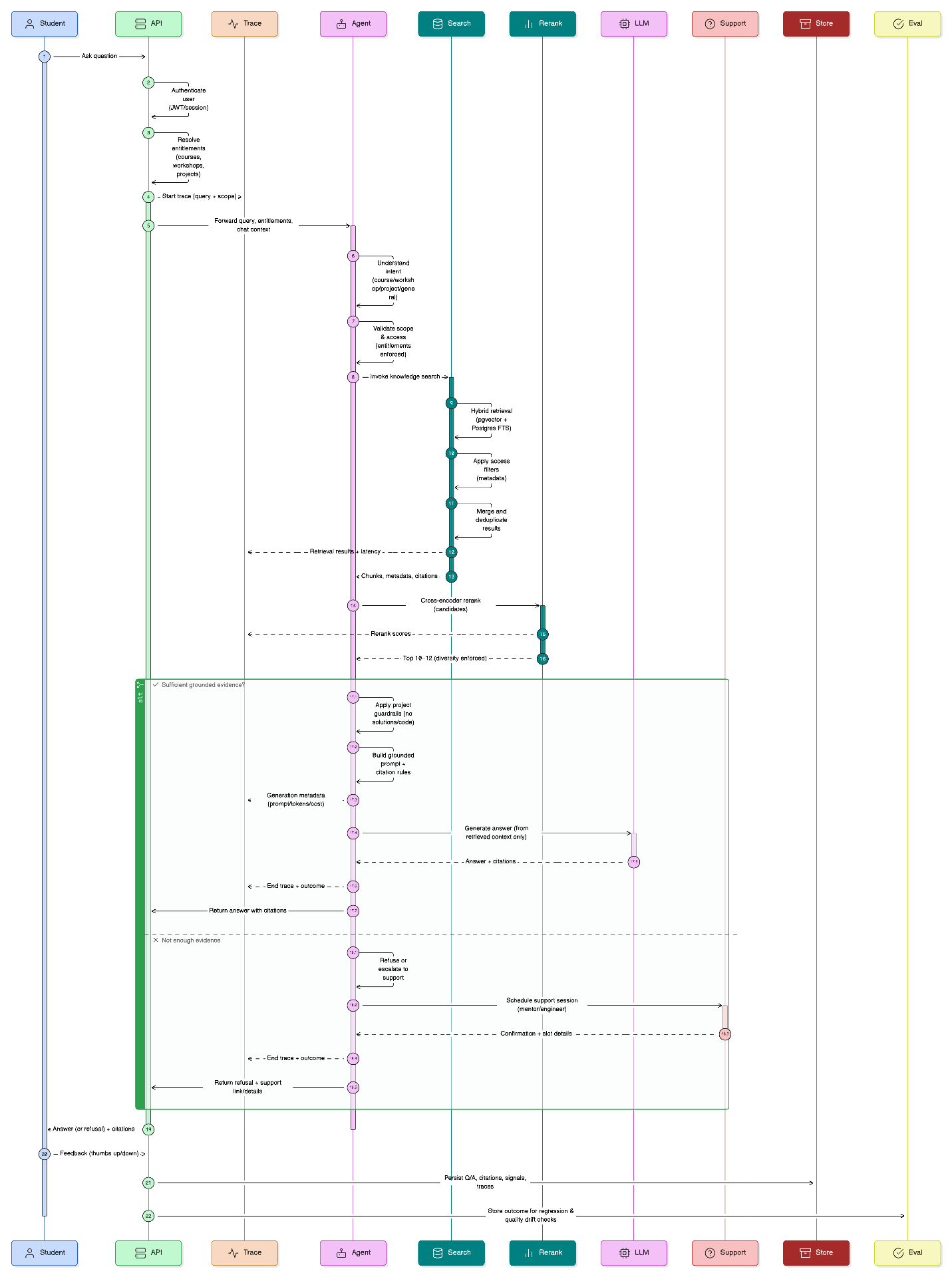
Complete System Flow
End-to-end query processing sequence diagram
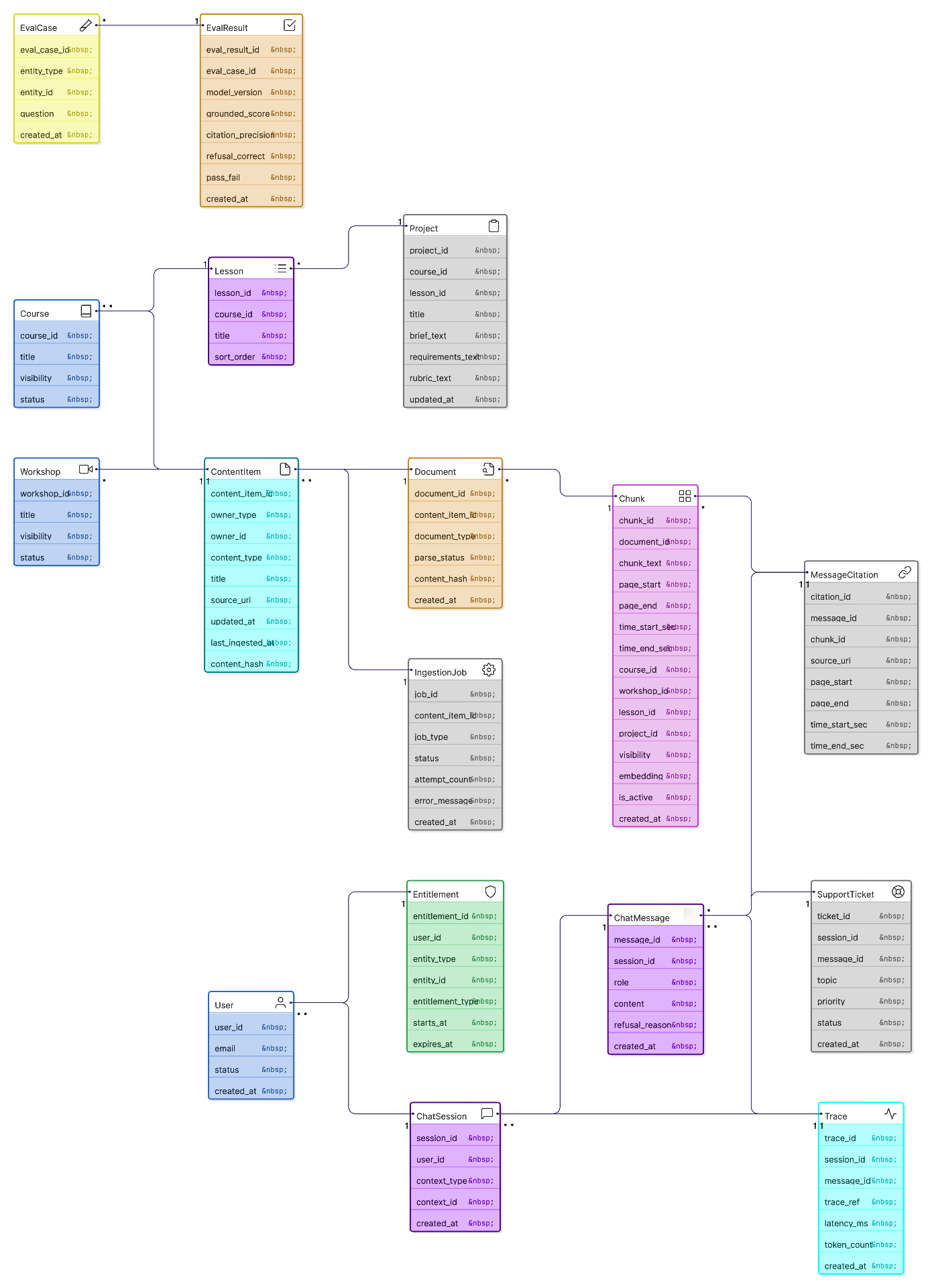
Simplified Data Model
Entity relationship diagram showing the core data structures
Conclusion
This engagement showcases Cybermind Works' ability to deliver production-ready AI systems built for real-world use and constraints. The platform functions as a core learning tool and integrates agentic orchestration, hybrid retrieval, and strict grounding and observability to provide accurate, citation-supported answers while preserving academic integrity and premium content quality.
Designed for continuous evolution, the system safely handles large content volumes, frequent updates, and evolving curricula without compromising reliability or learner experience.
About Us
Portfolio
Careers
CyberMind Works LLP
10/15, K.M Towers - 1st Floor, Chakrapani Road,
Guindy, Chennai, Tamil Nadu, 600042
Copyright © 2026, CyberMind Works | All rights reserved.